我们知道,CPU资源是有限的,任务的处理逻辑与线程个数并不是正相关。相反,过多的线程反而会导致CPU频繁切换,处理性能下降。所以,线程池的大小一般都是综合考虑要处理任务的特点与硬件环境,来事先设置的。
当我们向一个固定大小的线程池中请求一个线程时,如果线程池中没有空闲资源了,这个时候线程池如何处理这个请求?是拒绝请求还是排队请求?各种处理策略又是如何实现的?
其实,这些问题并不复杂,其底层的数据结构就是今天的内容,队列(queue)。
队列这个概念非常好理解,你可以把它想象成排队买票,先来的先买,后来的人只能站末尾,不允许插队。先进者先出,这就是典型的队列。
我们知道,栈只支持两个操作:入栈push()和出栈pop(),队列和栈非常类似,支持的操作只有:入队enqueue(),将一个数据放入队尾,出队dequeue(),从队头取出一个数据。
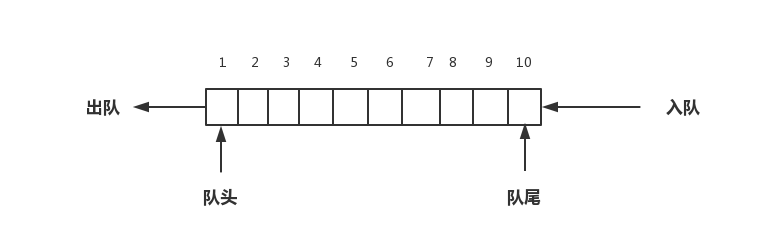
所以,队列跟栈一样,也是一种操作受限的线性表数据结构。
队列的概念很好理解,基本操作也很容易掌握。作为一种非常基础的数据结构,队列的应用也非常广泛。特别是一些具有额外特性的队列,比如循环队列、阻塞队列、并发队列。它们在很多片底层系统、框架、中间件的开发中,起着关键性的作用。比如高性能队列Disruptor、Linux环形存储,都用到了循环队列;java.concurent并发包中用到了ArrayBlockingQueue来实现公平锁等。
我们知道了,队列跟栈一样,也是一种抽象的数据结构。它具有先进先出的特性,支持在队尾插入元素,在对头删除元素,那么究竟该如何实现一个队列呢?
跟栈一样,队列可以用数组实现,也可以用链表实现。用数组实现的栈叫做顺序栈,用链表实现的栈叫做链式栈。同样,用数组实现的队列叫做顺序队列,用链表实现的队列叫做链式队列。
先来看下基于数组的实现方法。我这里采用java语言进行实现,不会涉及高级语法。
1 | // 基于数组实现的队列 |
比起栈的数组实现,队列的数组实现稍微有点复杂。
对于栈来说,我们只需要一个栈顶指针就可以了,但是队列需要两个指针:一个head指针,指向队头;一个tail指针,指向队尾。
你可以结合下面这幅图来理解。当a、b、c、d…依次入队之后,指针中的head指针指向下标为1的位置,tail指针指向下标为7的位置。
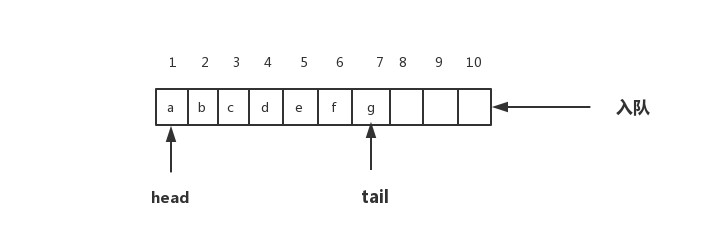
当我们调用两次出队操作之后,队列中的head指针指向下标为5的位置,tail仍然指向下标为7的位置。
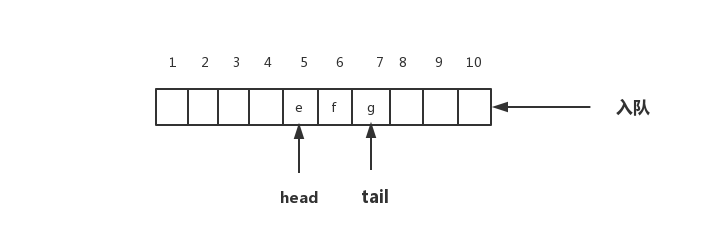
你肯定已经发现了,随着不停的入队、出队操作,head、tail都会持续往后移动。当tail移动到最右边,即使数组中还有空闲空间,也无法继续往队列中添加数据了。这个问题如何解决呢?
在数组那一节中,我们遇到过同样的问题,数组的删除操作会导致数组中的数据不连续,还记得我们怎么解决得吗?数据搬移!,但是每次出队时都相当于删除数组下标为0的数据,要搬移整个队列中的数据,这样队列的出队时间复杂度就从原来的O(1)变为了O(n),能不能优化呢?
实际上,我们在出队时可以不用搬移数据,如果没有空闲空间了,我们只需要在入队时,在集中触发一次数据的搬移操作。借助这个思想,出队函数保持不变,我们稍加改造一下入队函数enqueue()实现,就可以轻松解决刚才的问题了。
1 | public boolean enqueue(T val){ |
从代码中我们可以看到,当队列tail指针移动到数组的最右边后,且数组没有满时,如果有新的数据入队,我们可以将head-tail之间的数据,整体搬移到0-size之间的位置,
这种思路中,出队的时间复杂度仍然是O(1),但是入队的时间复杂度还是O(n)吗?此处用以前讲过的摊还分析法自行分析一下。
接下来,我们看看基于链表的队列的实现方法。
基于链表的实现,我们同样需要两个指针:head指针和tail指针。他们分别指向第一个结点和最后一个结点。入队时,tail->next = newNode, tail = tail->next;出队时,head = head->next。
我将具体代码放到我的github上,有需要的可以看看。
我们上面用数组实现的队列,在tail=capacity的时候,会有数据搬移操作,这样入队操作性能就会受到影响。那有没有办法能够避免数据搬移操作呢?我们来看看循环队列的解决思路。
循环队列,顾名思义,它长得像一个环。原本数组是有头有尾的,是一条直线,我们现在把首尾相连,掰成了一个环,可以通过下图直观感受一下。
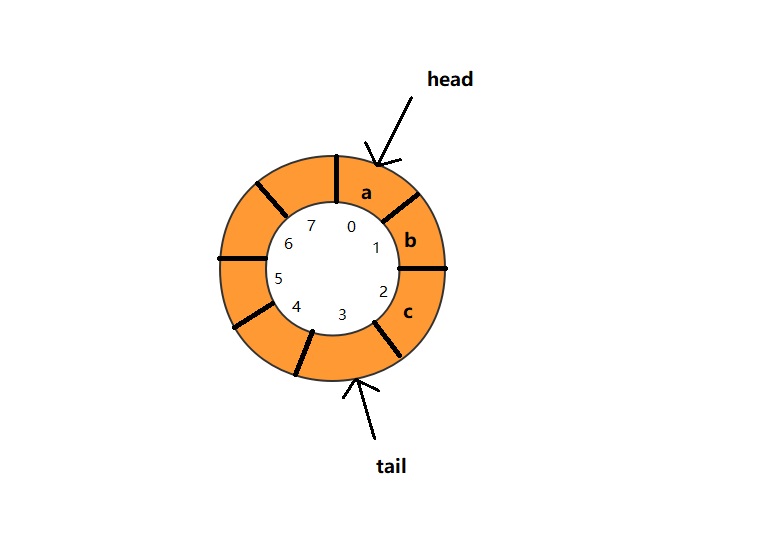
我们可以看到,图中这个队列的大小为8,当前head=0,tail=3.当有一个新的元素d入队时,我们放入到下标为3的位置,并将tail指向4。当tail指向7,这时候再有新的元素入队时,我们并不将tail更新为8,而是将tail指向0,如果再有元素入队,放入下标为0处的位置,并将tail更新为1。当然如果head=0处没有出队的话,就说明队列满了。
通过这样的方法,我们成功的避免了数据搬移操作,看起来不难理解,但是循环队列的代码实现难度要比前面讲的非循环队列难多了。要想写出没有bug的循环队列的实现代码,最关键的是,确定队列空和队列满的判定条件。
在用数组实现的队列中,对空的判定条件是head==tail,队列满的条件是tail==capacity。那针对循环队列,如何判断队满和队空呢?
队列为空的条件仍然是head==tail,但是队列满了的判断条件就复杂了,我画了如下一张队列满的图,可以看一下队满的规律。
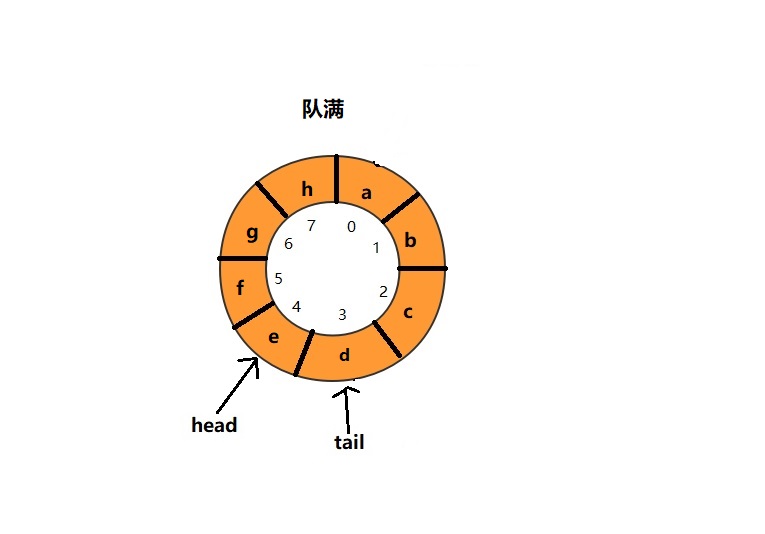
图中队列满时,tail=3,head=4,size=8,capacity=8,多画几张队满的图,就会发现队满时(tail+1)%capacity = head。同时,head和tail不能简单的使用++或者–,得出规律tail=(tail+1)%capacity,head=(head+1)%capacity。
下面看下一下循环队列的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49// 基于数组实现的循环队列
public class CircularQueue<T> implements Queue<T> {
// 数组items
private Object[] items;
// 队列大小
private int size=0;
private int capacity;
// head表示队头下标,tail表示队尾下标
private int head=0;
private int tail=0;
public CircularQueue(){
this(10); // 队列默认容量给10
}
public CircularQueue(int capacity){
this.items = new Object[capacity];
this.capacity = capacity;
}
public boolean enqueue(T val){
if ((tail+1)%capacity == head){
throw new RuntimeException("循环队列满了!");
}
items[tail] = val;
tail = (tail+1)%capacity;
size ++;
return true;
}
public T dequeue(){
if (size<=0){
throw new RuntimeException("空队列!");
}
T res = (T) items[head];
size--;
head = (head+1)%capacity;
return res;
}
public String toString() {
return Arrays.toString(items);
}
public int size() {
return size;
}
}
上面讲的都是些理论知识,看起来很难跟实际项目扯上关系,确实,队列这种数据结构很基础,平时的业务开发不大可能从零开始实现一个队列,甚至都不会直接用到。而一些具有特殊特性的队列应用却比较广泛,如阻塞队列和并发队列。
阻塞队列其实就是在队列基础上增加了阻塞操作。简单来说,就是在队列为空的时候,从对头取数据会被阻塞。并未此时还没有数据可取,直到队列中有了数据才能返回;如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后在插入数据,然后在返回。
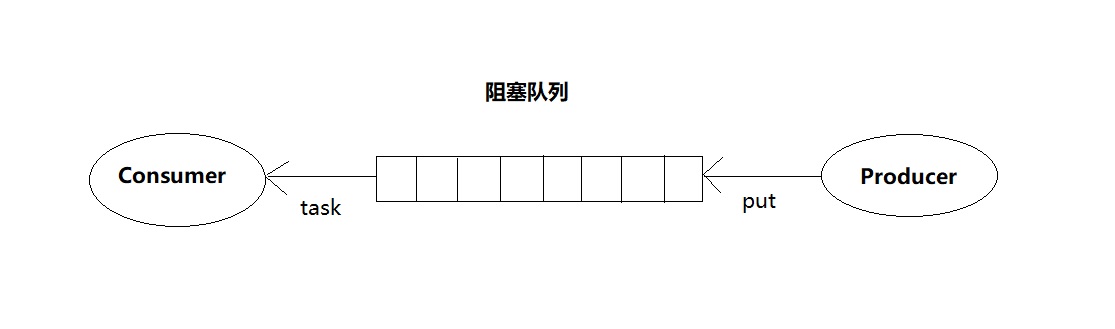
你应该已经发现了,上述的定义就是一个”生产者-消费者模型”!是的,我们可以用阻塞队列轻松实现一个”生产者-消费者模型”。
这种基于阻塞队列实现的”生产者-消费者模型”可以有效的协调生产和消费的速度。当”生产者”生产数据的速度过快,”消费者”来不及消费时,存储数据的队列很快就会满了,这个时候,生产者就阻塞等待,直到”消费者”消费了数据,”生产者”才会被唤醒继续生产。
而且不仅如此,基于阻塞队列,我们可以通过协调”生产者”和”消费者”的个数,来提高数据处理的效率。比如前面的例子,我们可以配备多个”消费者”,来对应一个”生产者”。
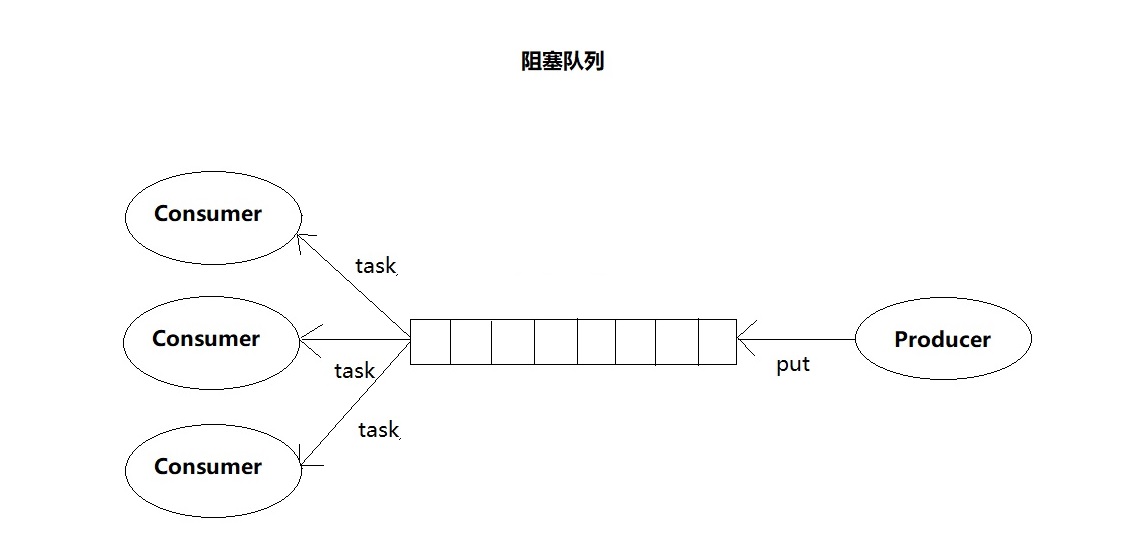
前面讲了阻塞队列,在多线程情况下,会有多个线程同时操作队列,这个时候就会存在线程安全问题,那如何实现一个线程安全的队列呢?
线程安全的队列我们叫做并发队列。最简单直接的实现方式是直接在enqueue()、dequeue()上加锁,但是这样锁粒度大并发较低,同一时刻仅允许一个村或者取操作。实际上,基于数组的循环队列,利用CAS原子操作,可以实现非常高效的并发队列。这也是循环队列比链式队列应用更加广泛的原因。
队列的知识讲完了,我们来看一下开篇的问题。线程池没有空闲线程时,新的任务请求线程资源时,线程池该如何处理,各种处理策略又是如何实现的呢?
我们一般有两种处理策略。第一种是非阻塞的处理方式,直接拒绝任务请求;另一种是阻塞的处理方式,将请求进行排队,等到有空闲线程时,取出队列中的请求继续处理。那如何存储排队的请求呢?
我们希望公平的处理每个排队的请求,先进者先出,所以队列这种数据结构很适合存储排队请求。我们前面说过,队列有基于链表和基于数组这两种方式,那这两种实现方式对于排队请求又有什么区别呢?
基于链表实现的方式,可以实现一个支持无限排队的无界队列,但是可能会导致过多的请求排队等待,请求处理的响应时间过长。所以,针对响应时间较敏感的系统,基于链表实现的无限排队的线程池是不合适的。
而基于数组实现的有界队列,队列的大小有限,所以线程池中排队的请求超过队列大小时,接下来的请求就会被拒绝,这种方式对响应时间敏感的系统,就相对来说比较合理。不过设置一个合适的队列大小,也是非常有讲究的。队列太大导致等待的请求太多,队列太小会导致无法充分利用系统资源,发挥最大性能。
除了前面讲到的应用在线程池请求排队的场景之外,队列还可以应用在任何有限资源池中,用于排队请求,比如数据库连接池。实际上,对于大部分资源有限的场景,当没有空闲资源时,基本上都可以通过队列这种数据结构来实现队列请求排队。
今天我们讲了一种跟栈很相似的数据结构,队列。
队列最大的特点就是先进先出,主要的两个操作是入队和出队。跟栈一样,它既可以用数组来实现,也可以用链表来实现。用数组实现的叫顺序队列,用链表实现的叫链式队列。特别是一个长得像环一样的叫循环队列。在用数组实现的队列时,会有数据搬移的工作,要想解决数据搬移的工作,我们就需要像环一样的循环队列。
循环队列是这篇的重点,要想写出没有bug的循环队列的实现代码,关键是要确定队满和队空的判定条件。
除此之外,还有几种高级的数据结构,阻塞队列、并发队列,但是底层都是队列这种数据结构,只不过附加了其他的一些功能。阻塞队列就是可以对出队、入队操作进行阻塞,并发队列就是保证了多线程的队列操作线程安全。
1、 除了线程池这种池结构会用到队列排队请求,你还知道那些类似的数据结构或者场景会用到队列的排队请求。
如数据库的连接池、分布式应用中的消息队列(kafka、MQ)
2、 关于并发队列,如何实现无锁的并发队列。
提示: CAS(compare and swap) 乐观锁 悲观锁